
Licensed bitstream subscription
Turn supported FPGA platforms into ML inference experimentation or product deployments through a licensed bitstream subscription: recurring bitstream drops, a compiler aligned to each release, and tooling for bring-up and regression. The LEO execution core targets inference (not training), with CSM hooks for configuration, status, and performance counters so runs are observable—not a black box.
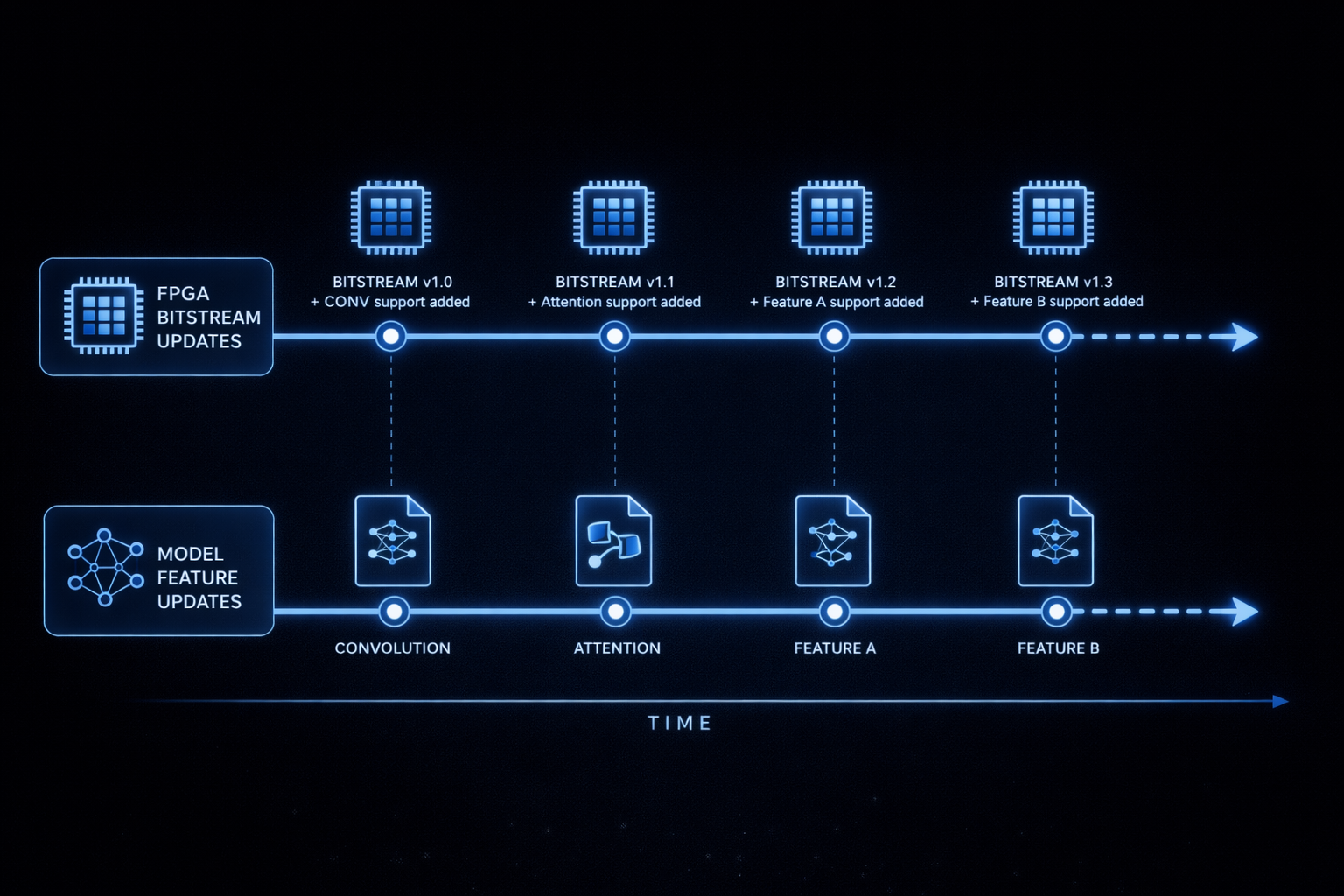
When this model fits: teams that need strong security or supply-chain control (distribution and review under license), or whose models or feature roadmap move faster than a fixed silicon cycle. You avoid committing to immutable inference hardware; instead you refresh accelerator capability on demand as compiler and RTL features ship. Performance is engineered so that, on supported graphs and qualified boards, inference can match or beat GPU baselines—something we expect partners to validate with CSM-backed benchmarks rather than taking as a generic web claim.
What the program is for
- Research & product teams evaluating or shipping inference on FPGA before ASIC or deeper integration.
- Security-conscious programs where bitstream provenance, controlled releases, and auditable tooling matter.
- Rapid model churn—new ONNX checkpoints, ops, or precision modes—without waiting for new silicon each time.
- Lab automation for inference workloads: repeatable builds, configuration IDs, and CSM-backed captures.
- Teaching and benchmarking where hardware-faithful inference behavior matters more than peak marketing numbers.
Included themes
- Bitstream releases for agreed device / board families (contact for current matrix).
- Compiler access matching the subscribed ISA and core configuration set.
- CSM host interface for configuration, status, and performance counters.
- Documentation and support tiers negotiated per subscription level.
We do not publish generic GPU-versus-FPGA league tables on the open web; we emphasize agreed device and model classes, full compiler flow, and CSM-measurable runtime and utilization so you can verify inference performance—including GPU comparisons—in your own lab under NDA where appropriate.
Next step
Tell us your target board, model families, and whether you need partnership-style measurement or evaluation-only access.