
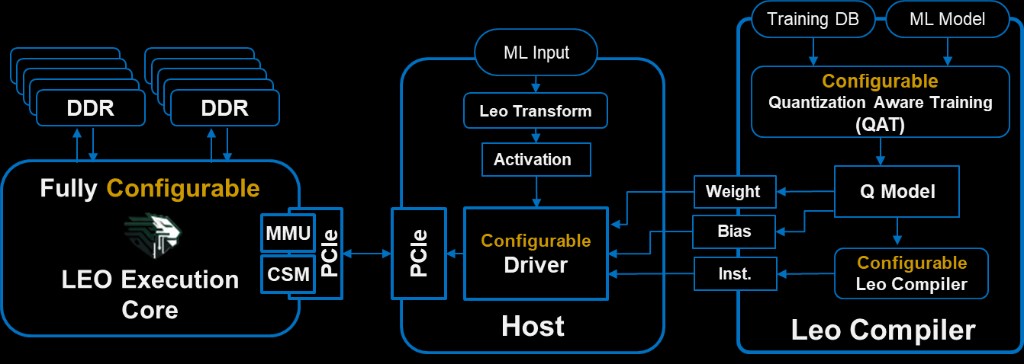
Leo Execution Core
This column is the RTL / silicon catalog we configure for each FPGA or ASIC target—fixed at generation time. It spans datapath, PE/MAC grades (performance / power / area), array shape, on-chip storage, activations, LLM-oriented units (layer norm, LUT SoftMax, transpose paths, and related parameters), instruction decoder (fetch / decode / issue), external DRAM/HBM, and PCIe host attach. Host-visible CSM gives observability and control (see note below the list). For transformers, those LLM blocks supply the primitives the Leo Compiler maps onto; the same core stays useful when the workload is not attention-heavy. Bullets are representative—the real space is larger and not limited to what is shown.
Processing core logic — BUS
- DATA width — 4, 8, 16, …; readily extended to custom widths.
- Accumulation width — arbitrary size (typical default 32).
Processing many-core
- Core dimension — 2×2, 4×4, 8×8, 16×16, 32×32, 64×64, 128×128, 256×256, …
PE MAC type & grades
- PE / MAC implementation grades—catalog choices that trade performance, power, and area (e.g. higher-throughput vs denser low-leakage variants) selected at RTL generation time.
- Leo specialized ultra-efficient core—optional MAC/PE style optimized for energy and area when the program targets maximum efficiency; remains on the same ISA family so the Leo Compiler flow stays consistent across grades.
Internal storage
- Global buffer depth / capacity parameters.
- Partial result buffer depth / capacity parameters.
Vectorized ALU
- Compile-time selection of which functions the ALU exposes across a menu of supported operations—chosen when the core variant is generated.
Activation
- ReLU, quantization-only paths, and extendable activation families.
- Activation + residual add fusion—fused regions where dependencies and the datapath allow.
- LUT-based custom activations—table geometry and interpolation matched to compiler and accuracy targets.
- Rounding mode as a configurable choice per activation path (e.g. toward zero, nearest, stochastic) where the RTL variant supports it.
- Further activation modes as the catalog grows.
LLM-related hardware parameters
- Layer normalization — LUT size and width; internal BUS (distinct from DATA and partial-sum path); error recovery via Newton–Raphson; enable, iteration count; I/O matched to DATA and Result BUS.
- SoftMax (LUT-based) — quantization settings; LUT size and width; internal BUS size; mean / variance compute sizing; inputs and outputs matched to DATA and Result BUS.
- Transpose — automatically configured with processing core and BUS; further options as the catalog grows.
Instruction decoder (fetch / decode / issue)
- Input instruction buffer size.
- Instruction window size—how many instructions are visible for parallelism exploration and dependency analysis in the issue logic.
- Instruction packet size—alignment with host link framing (e.g. PCIe).
- Instruction compression and packing—optional encodings for denser streams and better PCIe utilization.
External DRAM / HBM memory interface
- Unified vs separate channels—traffic classes, dedicated paths for partial sums vs global buffer vs host-visible regions as configured.
- Number of DRAM interfaces and bandwidth per channel (width, rate, burst behavior).
- Support for heterogeneous DRAM and parallel write patterns where the memory subsystem allows.
- DRAM addressing length—variable support for how many address bits (and which map semantics) the interface exposes to software.
- Controller buffer sizing; read/write burst sizes; memory behavior control.
- LUT-adjacent interface hooks where tied to SoftMax, LayerNorm, and similar units.
PCIe host attach
- Number of PCIe channels / port instances (as integrated in the macro).
- Width and sizing per channel—lanes per link, effective data width, buffer depth, and packet framing.
- Lane count, bits per lane, and PHY/link parameters matched to board and SoC assumptions.
- Instruction packet mapping from PCIe framing to the instruction ingress path (see instruction decoder above).
The CSM (configuration and status module) is the host-facing path for visibility into core operation—counters, status, and configuration—together with interrupt-based event handling and shared resource management (for example coordination when DRAM, ingress, and on-chip buffers are visible to both host and core). It is not enumerated line-by-line here; partners tune CSR maps, mutex policies, and counter banks per integration.